My last post was about searching with a test penalty. The problem boils down to minimizing a recursive difference equation. Since I didn’t (and still don’t) have a closed-form solution, I had to base any conclusions on brute-force tests that find the best tree. The run time was dreadfully slow so I could calculate the solution for no more than a 15-cell array. For small arrays and a small cost constant, the solution for linear cost is just a half-interval search tree.
After writing that post I realized several things and here are the new results.
As suggested by several people, the solution can be found more efficiently using dynamic programming. I’ve implemented a revised version of the code that finds the solution by recursively finding it for subtrees. It runs much faster after this change. The DP approach also eliminates the space leak – the program uses very little memory. Also, I’ve added parallelization with a tiny bit of code using parMap to cut the execution time by a factor of 4 (on my core i5). It’s pretty cool how easy it is to parallelize purely functional code! After these changes, calculating an array one cell larger takes almost exactly three times longer.
Here’s my theory for why three times longer. Since we split the array at the test index and have two branches for each possible root node, an array of size n requires solving the subtrees for arrays of sizes 1 through n-1, twice [see note 1]. So, relative to the n-1 case we have at least twice as much work (for the two extremities that have n-1 sized sub-arrays). Additionally we have the twice the sum from 2 to n-1 of 2^-x amount of work to do (relative to the n-1 case) for the smaller sub-arrays, which converges very quickly to 1. In total, we need to do 3 times as much work when using the DP approach.
With the improved code I’ve calculated the solutions for slightly larger arrays. Here are the results for the range [0,17] (an array of size 18):
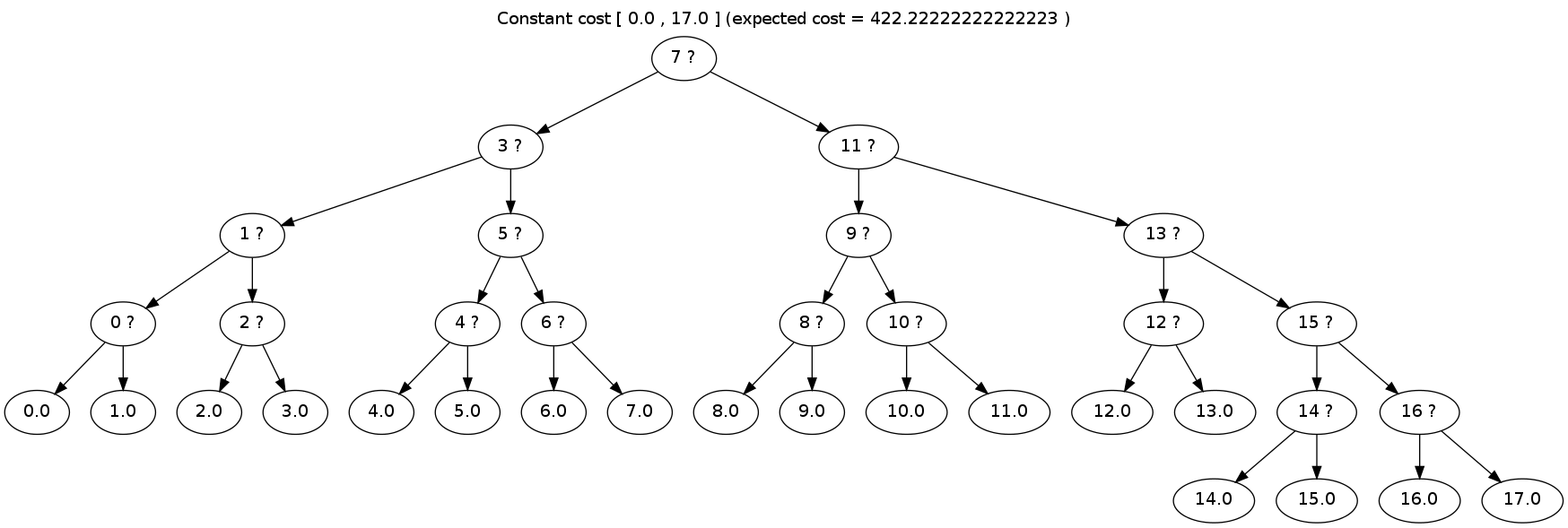


Revised recommendation for confectionery research
Ok, I’ll skip the soufflé analogy this time. Assuming a monotonically increasing cost function, a good strategy is what you’d expect: prioritize searching in the lower-costing area, using some sort of biased interval search (rather than half interval).
Open question still…
I’m still looking for a closed-form solution to the cost equation. For those who didn’t read the last post, the problem is to find the search tree that minimizes the expected cost of a search on an array, where each test carries a cost (given by a cost function). To solve the problem, one must minimize the following value by picking the optimal test point t depending on the current range [x,y]:

The simplifying assumptions were uniform distribution of the search target, and linear cost:
Another possible simplification: assume that the search algorithm uses a constant ratio to pick the next search target. That is, for a range [x,y] the next search target will always be c * (y – x + 1) (rounded down) where c is a constant, between 0 and 1. I’ve toyed around with this one but ended up with the same basic problem – how to solve recursive equation?
The code is now up on github for your doubtless enjoyment.
Comments welcome!
1. The algorithm is a bit smarter – there’s no need to test the last array index, so the number of tests is slightly reduced.

My experiments strongly suggest that:
E[cost(1,y)] = Θ(log y) for constant cost
E[cost(1,y)] = Θ(y*log y) for linear cost
E[cost(1,y)] = Θ(y^2*log y) for quadratic cost
But I haven’t proved anything of the sort yet. I dumped the code at https://gist.github.com/twanvl/4944663
I also get slightly different trees for non-constant costs. In particular, with linear cost, the tree first tests 0?, which makes sense, since that has no cost.
[…] previous post – a second in a series discussing optimal search under test penalty – concluded with an […]